LipVoicer: Generating Speech from Silent Videos
Guided by Lip Reading
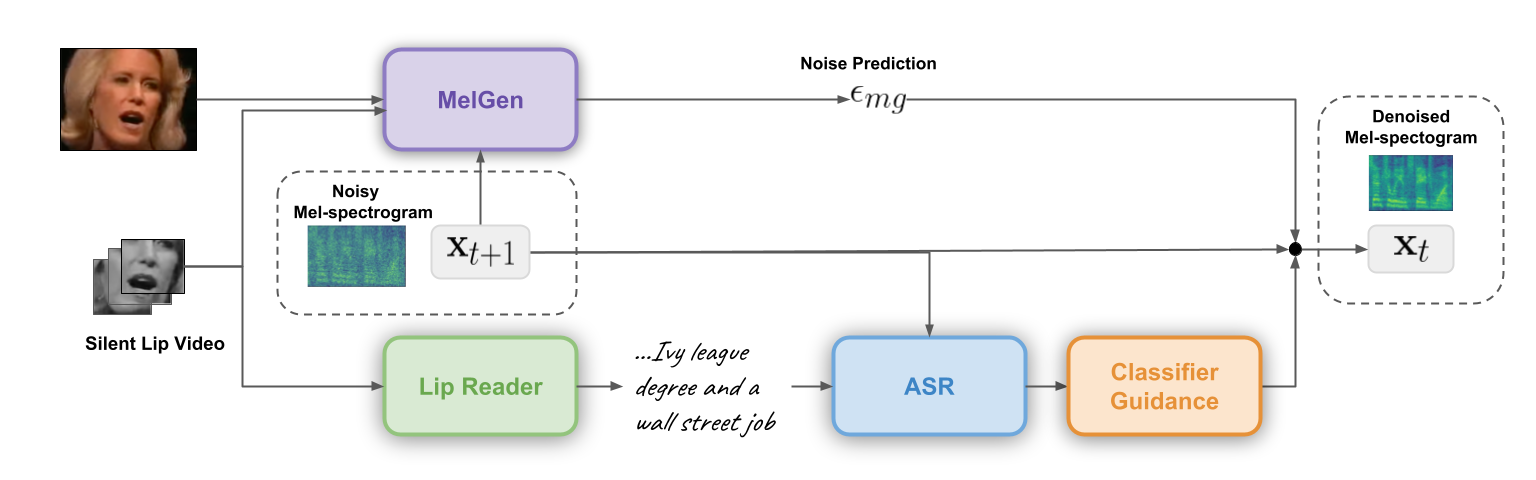
Lip-to-speech involves generating a natural-sounding audio synchronized with a soundless video of a person talking. Despite recent advances, current methods still cannot produce high-quality speech with high levels of intelligibility for challenging and realistic datasets such as LRS3. In this work, we present LipVoicer, a novel method that generates high-quality speech, even for in-the-wild and rich datasets, by incorporating the text modality. Given a silent video, we first predict the spoken text using a pre-trained lip-reading network. We then condition a diffusion model on the video, and use the extracted text through a classifier-guidance mechanism to produce the natural underlying mel-spectrogram, where an automatic speech recognition system (ASR) serves as the classifier. LipVoicer outperforms multiple lip-to-speech baselines on LRS3 and LRS2, which are in-the-wild datasets with hundreds of identities and an unrestricted vocabulary. Moreover, our experiments show that the inclusion of the text modality plays a major role in the quality and intelligibility measures, as well as in the reduction of word error rate (WER) metric of the generated speech. Finally, we demonstrate the effectiveness of LipVoicer through human evaluation, which shows that it produces more natural and synchronized speech signals compared to competing methods.